 软件星级:4分
软件星级:4分
标签: 文字识别
Text Extractor For Mac破解版是一款出色的文字识别软件,能够从PDF或者图像中提取文本。它具备很多高级OCR功能,支持上十种语种的检测,在印刷打印行业运用得很多。
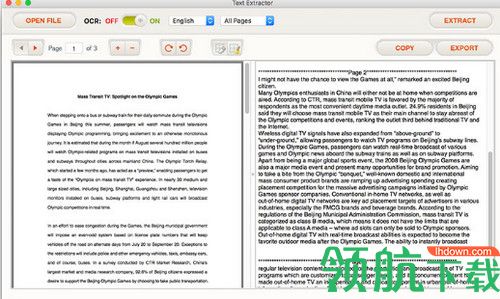
Mac的文本提取器可帮助您将扫描的PDF文档,数字图像转换为可搜索和可编辑的文本内容。它可以通过先进的OCR(光学字符识别)技术消除您的重新键入工作,该技术可以准确地从图像中识别文本并有效地提取文本内容。
1、将PDF和图像转换为可搜索和可编辑的文本内容
如果您有扫描的PDF或图像文件,这会很沮丧,如果要获取信息,则必须手动重新输入。
使用文本提取器,您可以解锁文本内容,轻松获取和使用PDF文件中锁定的信息。从图像或扫描的PDF中提取文本非常容易。
2、先进的OCR功能
当您扫描纸质文档并将其另存为PDF或图像文件时,实际上所有内容都会被捕获为图像,而不是文本和字体信息,OCR技术用于文本识别和提取。
准确性是OCR应用程序的核心,如果源文件具有高质量,则文本提取的识别准确性可以达到90%。节省转换后纠正错误的时间。
文本提取器可以检测10种语言,包括英语,法语,德语,意大利语,瑞典语,俄语,波兰语,荷兰语,西班牙语,葡萄牙语。
3、直观的界面,易于使用
OCR转换不是一件容易的事,但是通过易于使用的界面,您可以用更少的步骤完成提取。
打开PDF或图像文件,
打开OCR并选择文档语言,
点击“提取”按钮开始OCR识别,
完成后,您可以将文本复制到剪贴板或将其导出为.txt文件。
4、高效转换
文本提取器可有效地将大型PDF文档和图像转换为可编辑和可搜索的文本,并更快地传递转换后的文本内容。如果未启用OCR,则从未扫描的PDF文件提取每一页需要不到1秒的时间。
它使您可以直接在内置文本编辑器中编辑和修改提取的文本内容,并检查语法和拼写。检查后,您可以将内容复制到剪贴板中并导出为纯文本(.txt)。
步骤1:启动应用程序并打开一个文件
打开Finder>应用程序,然后单击“文本提取器”图标。当界面出现时,单击“打开文件”按钮。然后,您可以从下拉查找器窗口中选择要执行提取的文件。
步骤2:选择输出和OCR选项
如果导入的文件不是扫描文件或图像,则无需启用OCR选项并选择文档语言。
如果您导入图像文件或扫描的PDF文件,请启用OCR,选择正确的文档语言。
提示:如何区分扫描的PDF文件和普通文件>>
您可以选择转换所有页面或当前页面。
步骤3:开始提取
点击“提取”按钮,转换将开始。
步骤4:使用提取的文本内容
提取过程完成后,您将在输出区域中看到文本内容。您可以直接在输出区域中编辑内容,将文本内容复制到剪贴板,或将其提取为纯文本文件(.txt)。
提取码: 4rwq
 57.02MB
33MB
57.02MB
33MB
 161MB
2.22MB
9.22MB
161MB
2.22MB
9.22MB













 迅雷极速版
迅雷极速版 网易邮箱大师
网易邮箱大师 夜神模拟器
夜神模拟器 搜狗拼音输入法
搜狗拼音输入法 世界之窗浏览器
世界之窗浏览器 网易CC语音
网易CC语音 游侠对战平台
游侠对战平台 UC浏览器
UC浏览器 金山毒霸
金山毒霸 微信电脑版
微信电脑版 360压缩
360压缩 网易云音乐
网易云音乐 有道云笔记
有道云笔记 FastStone Capture
FastStone Capture 格式工厂
格式工厂 万能五笔输入法
万能五笔输入法 微软常用运行库
微软常用运行库 YY语音
YY语音 飞书文档
飞书文档 腾讯视频会议
腾讯视频会议 CPU-Z
CPU-Z 傲梅分区助手
傲梅分区助手 IDM中文版
IDM中文版 DirectX修复工具
DirectX修复工具 360驱动大师
360驱动大师 Snipaste
Snipaste 360壁纸
360壁纸 口袋动画PPT插件
口袋动画PPT插件 WPS Office
WPS Office 金山PDF阅读器
金山PDF阅读器 360手机助手
360手机助手 Root精灵
Root精灵 iTunes
iTunes 同步助手
同步助手 奇兔刷机
奇兔刷机 飞火动态壁纸
飞火动态壁纸 腾讯桌面整理
腾讯桌面整理 酷点桌面美化
酷点桌面美化 搜狗壁纸
搜狗壁纸 雨滴桌面秀
雨滴桌面秀 百度拼音输入法
百度拼音输入法 搜狗拼音输入法
搜狗拼音输入法 手心拼音输入法
手心拼音输入法 QQ拼音输入法
QQ拼音输入法 微软拼音输入法
微软拼音输入法 BandiZip
BandiZip 精灵虚拟光驱
精灵虚拟光驱 PowerISO
PowerISO 7-Zip
7-Zip 智图压缩
智图压缩 DiskGenius
DiskGenius SSD Fresh
SSD Fresh 万能低格工具
万能低格工具 安易数据恢复
安易数据恢复 CrystalDiskInfo
CrystalDiskInfo 下图高手
下图高手 可牛影像
可牛影像 Xnview
Xnview 图片去水印工具
图片去水印工具 2345看图王
2345看图王