 软件星级:4分
软件星级:4分
标签: 数据采集
懒人采集器是一款非常智能的数据采集软件。使用它不需要编程,很容易创建,采集数据就是如此的简单。它专门为懒人而准备,没有比这更简易的采集工具了。支持各种网站。
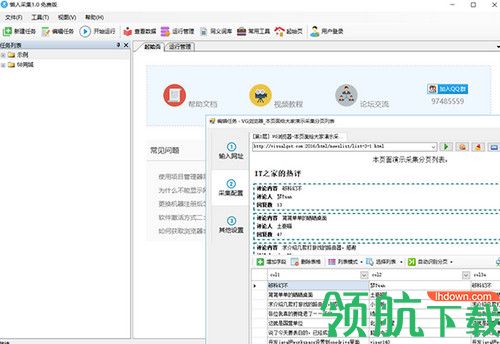
懒人采集器是一款简单易用、功能强大的网页采集工具。采集配置非常简单,全程可通过内置浏览器可视化选取需要采集的内容,使您可以在短时间内就可以快速创建出一个采集任务,无需分析网页源代码,更不需要熟悉网络协议,只需要点点鼠标就可以完成创建好任务。
1、软件操作简单,可通过鼠标点击的方式轻松选取要抓取的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化后的火狐浏览器,加上独创的内存优化使浏览器采集也可以高速运行,甚至可以快速转换为HTTP方式运行,享受更高的采集速度!而在抓取JSON数据时,同样可以使用浏览器可视化方式,通过鼠标点选需要抓取的内容,完全不需要去分析JSON数据结构,使非网页专业设计人士也可以轻松抓取需要的数据;
3、不用分析网页请求和源代码,却支持更多的网页采集;
4、先进的智能算法,可以一键生成目标元素X自动识别网页列表、自动识别分页中的下一页按钮……
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过向导的方式简单映射字段,即可轻松导出到目标网站数据库中。
1、可视化向导
所有采集元素,自动生成采集数据
2、智能识别
可自动识别网页列表、采集字段和分页等
3、计划任务
灵活定义运行时间,全自动运行
4、拦截请求
自定义拦截域名,方便过滤站外广告,提高采集速度
5、多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
6、多种数据导出
可导出为Txt 、Excel、MySQL、SQLServer、 SQlite、Access、网站等
第一步:设置起始网址
要采集一个网站的数据,首先我们要设置从哪些网址进入采集,比如我们要采集一个网站的国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,而一般不会设置网站首页为起始网址,因为首页通常会包含很多列表,比如最新文章、热门文章、推荐文章等等各种列表块,并且这些列表块里显示的内容也是非常有限的,采集这些列表的话一般都无法采集完整信息。
下面我们以采集新浪新闻为例,从新浪首页找到国内新闻,但该栏目首页内容还是比较杂乱,而且还细分三个子栏目

我们从进入其中一个子栏目“内地新闻”看一下
该栏目页包含有一个带分页的内容列表,通过切换分页,我们就可以采集到该栏目下的所有文章,所以这种列表页就非常适合作为我们采集的起始网址。
现在,我们就复制该列表网址到任务编辑框第一步的文本框中
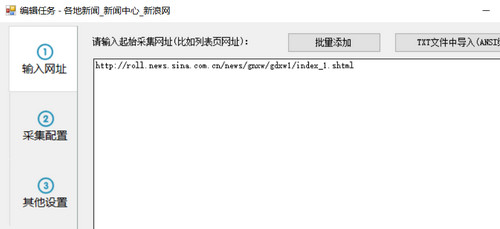
如果你要在一个任务中同时采集国内新闻里的其他子栏目,也可以把另两个子栏目列表地址复制进来,因为这些子栏目列表格式都是相似的。但为了便于导出或发布分类数据,一般不建议多个栏目内容混合在一起。
对于起始网址我们也可以批量添加或从txt文件导入,比如我们要采集前5页,也可以这样自定义五个起始页
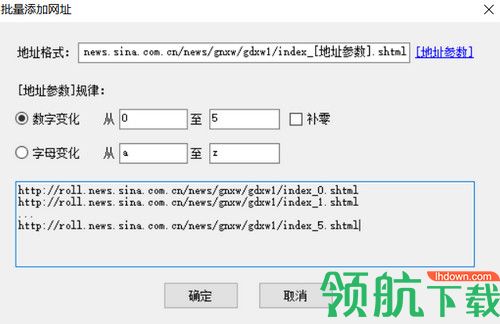
需要注意的是如果这里自定义了多个分页列表,在后面的采集配置里就不要再启用分页了,通常我们要采集某个栏目下的所有文章时,都只需要定义该栏目第一页为起始网址就行了,在后面的采集配置里启用分页,就可以采集到每个分页列表的数据。
第二步:自动生成列表和字段
进入第二步后,对于某些网页,懒人采集器会智能分析出该页的列表,并自动高亮选择网页列表和生成列表数据,如

然后我们再对这些数据进行修整,比如删掉一些不需要的字段
点击图示三角符号,会弹出该字段采集详细配置,点击上面的删按钮即可删除该字段,其余参数后面章节会独立介绍。
如果某些网页自动生成的列表数据并不是我们想要的数据,可以点击“清除字段”,把生成的字段全部清除。
第三步:分页设置
当列表有分页时,启用分页后就可以采集到所有的分页列表数据。
网页分页有两种
普通分页:存在分页条,并显示有“下一页”按钮,点击后可以进入下一页,如之前的新浪新闻列表里的分页
瀑布流分页:网页滚动条拉到底部时会自动加载下一页内容
如果是普通分页,我们选择尝试自动设置或手动设置
自动设置分页
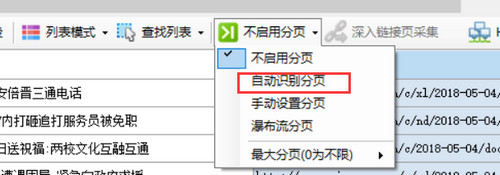
新建任务时默认是没有启用分页的,点击“不启用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出对话框提示“成功识别并设置了分页元素!”,并在网页“下一页”按钮上出现高亮的红色虚线框(部分网页按钮可能不会显示虚线框),至此成功启用自动分页。
第四步:其他设置
在第三步的基本设置里,我们可以对浏览器做一些设置,比如禁用图片、JS、Flash、框架等,提高浏览网页的速度。
还可以设置浏览器标识(UserAgent)、代理IP、请求的间隔时间等
浏览器标识(UserAgent):网页通过读取浏览器标识来获取客户端的一些信息
请求间隔时间:用于降低请求的频率,即降低采集速度,避免因采集太快而被封IP,如果不需要降速,可以设置为0时
多值连接符:字段设置了多个xpah提取多个元素时,使用这里自定义的连接符连接多个元素值
HTTP引擎线程数:使用HTTP请求时,多线程运行的线程数,同一个HTTP请求的任务可以拆分并使用多个线程同时采集,提高采集速度,只适用于HTTP引擎,浏览器引擎不适合。
1、采集时怎么避免重复到重复数据?
在运行某个采集任务时,如果该任务之前有采集过数据,那么采集前如果没有清空原有数据的话,会以追加的形式将新采集数据添加到本地采集库中,这样就可能出现某些已采集过的数据再次重复采集入库,还有,如果目标网页本身也重复的数据,也可能造成数据重复,那么怎么避免采集的数据出现重复呢?
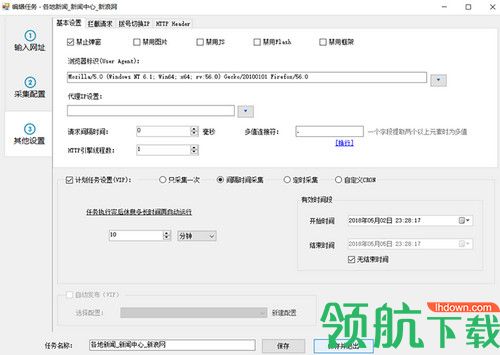
方法很简单,我们希望哪一个字段内容不允许出现重复,只要点击该字段表头上这个三角符号,再勾选“过滤重复”复选框,点击确定就可以了
2、如何采集内容页等多级网页
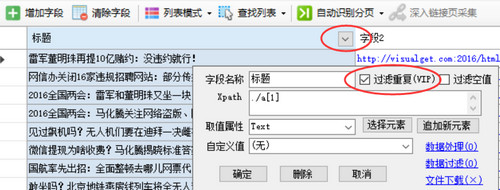
如果我们要采集二级页面,如内容页,或采集更深一级的页面,三级、四级等,在当前页字段列表中,必须包含有一个提取链接地址的字段,也就是提取属性为Href的字段,如图
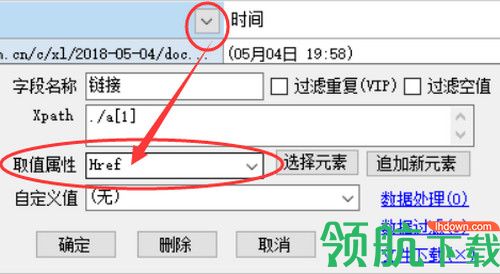
点击该字段标题栏,选中该列后会出现“深入链接页采集”按钮
点击该按钮后会自动创建一个配置选项卡,并自动打开之前选中那个字段的一个网址。
而采集模式也自动显示为“单条模式”














 迅雷极速版
迅雷极速版 网易邮箱大师
网易邮箱大师 夜神模拟器
夜神模拟器 搜狗拼音输入法
搜狗拼音输入法 世界之窗浏览器
世界之窗浏览器 网易CC语音
网易CC语音 游侠对战平台
游侠对战平台 UC浏览器
UC浏览器 金山毒霸
金山毒霸 微信电脑版
微信电脑版 360压缩
360压缩 网易云音乐
网易云音乐 有道云笔记
有道云笔记 FastStone Capture
FastStone Capture 格式工厂
格式工厂 万能五笔输入法
万能五笔输入法 微软常用运行库
微软常用运行库 YY语音
YY语音 飞书文档
飞书文档 腾讯视频会议
腾讯视频会议 CPU-Z
CPU-Z 傲梅分区助手
傲梅分区助手 IDM中文版
IDM中文版 DirectX修复工具
DirectX修复工具 360驱动大师
360驱动大师 Snipaste
Snipaste 360壁纸
360壁纸 口袋动画PPT插件
口袋动画PPT插件 WPS Office
WPS Office 金山PDF阅读器
金山PDF阅读器 360手机助手
360手机助手 Root精灵
Root精灵 iTunes
iTunes 同步助手
同步助手 奇兔刷机
奇兔刷机 飞火动态壁纸
飞火动态壁纸 腾讯桌面整理
腾讯桌面整理 酷点桌面美化
酷点桌面美化 搜狗壁纸
搜狗壁纸 雨滴桌面秀
雨滴桌面秀 百度拼音输入法
百度拼音输入法 搜狗拼音输入法
搜狗拼音输入法 手心拼音输入法
手心拼音输入法 QQ拼音输入法
QQ拼音输入法 微软拼音输入法
微软拼音输入法 BandiZip
BandiZip 精灵虚拟光驱
精灵虚拟光驱 PowerISO
PowerISO 7-Zip
7-Zip 智图压缩
智图压缩 DiskGenius
DiskGenius SSD Fresh
SSD Fresh 万能低格工具
万能低格工具 安易数据恢复
安易数据恢复 CrystalDiskInfo
CrystalDiskInfo 下图高手
下图高手 可牛影像
可牛影像 Xnview
Xnview 图片去水印工具
图片去水印工具 2345看图王
2345看图王