 软件星级:4分
软件星级:4分
标签: 数据采集
火车采集器是一款出色的网页数据采集软件。它能够识别很多的系统,不仅速度快而且十分安全。即使人不在电脑旁,它也能自动执行采集工作,很人性化。采集的内容和数量没有任何限制。
火车采集器是一款专业的互联网数据抓取、处理、分析,挖掘软件,可以灵活迅速地抓取网页上散乱分布的数据信息,并通过一系列的分析处理,准确挖掘出所需数据。火车采集器历经十二年的升级更新,积累了大量用户和良好口碑,是目前最受欢迎的网页数据采集软件。
1、多线程高速并行采集系统
任务分配至多个客户端,同时运行采集,效率倍增。
2、多识别系统
配备正文识别、中文分词识别、任意编码识别等多种识别系统,智能识别操作更轻松。
3、可选验证方式
可选择是否使用加密狗,随时保障数据安全。
4、全自动运行
无需人工值守操作,任务完成后自动关机
5、替换功能
同义,近义词替换、参数替换,伪原创必备技能。
6、任意文件格式下载
图片、压缩文件、视频等任意格式的文件都能轻松下载。
7、支持多数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle多种类型的数据库保存及发布。
8、无限级多页采集
支持包含ajax请求数据在内的多个页面信息的无限级采集。
采集器提供了插件机制,来增强数据采集、数据处理的能力。 目前插件按照功能分为3种:HTTP请求插件、内容数据插件、文件下载插件,下面介绍下C#源码类型的插件。
HTTP请求插件
可以修改HTTP请求前的请求数据(http header)和HTTP完成后的返回数据(response),这个插件包含了2个处理方法。
BeforeRequest(RequestEntry request)
这个方法会在所有HTTP请求前的调用,包括网址采集、内容采集请求,可以通过修改请求来应对一些复杂的网站抓取。
参数介绍:
request 参数中包含Url、Referer、Cookie、Headers、页面类型等,除HTTP基本属性外,还有包含一些特殊值
request.Properties["PageType"], 这个属性是页面类型,值为整数类型,包含6种类型
0:起始地址; 1:列表页面; 2:列表页的分页; 3:内容页面; 4:关联多页; 5:内容页的分页;
request.Properties["JobName"],任务名称
request.Properties["JobID"],任务ID
request.Properties 属性最好只做读取操作,不要修改,不然会造成无法预料的结果。其他的RequestEntry字段请参考 [文章最后]
AfterResponse(ResponseEntry response)
这个方法在所有HTTP请求完成后调用,可以修改为自己想要的数据,然后交给采集器来处理。
参数介绍:
response中包含HTTP响应数据,如返回HTML、响应Header
response.RawText`,是返回的HTML代码
response.Url`,请求的Url地址
和 request 一样,response 也包含了 response.Properties["PageType"]、request.Properties["JobName"]、request.Properties["JobID"],含义相同。
其他的ResponseEntry字段请参考 [文章最后]
示例插件代码:

网址采集规则
采集规则制作的第一步骤,点击向导添加,①➯②,出现如图界面。
分3种方式:普通网址,批量网址,文本导入。
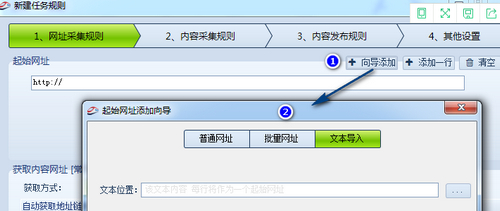
a.普通网址:以一行一个的形式直接加入网址,不做任何解析。
b.批量网址:以通用的表达式批量生成网址。
c.文本导入:以文本导入的形式,文本为一行一个的网址。
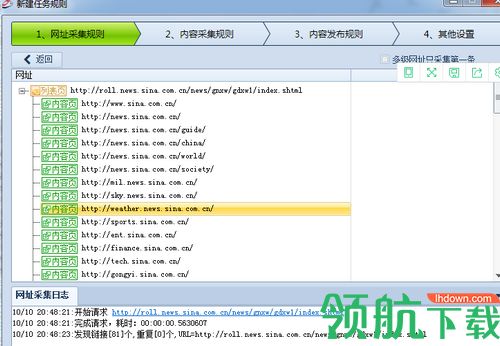
获取内容网址
[常规模式]a.自动获取地址链接
自动获取地址链接:自动获取该级列表页中所有的a标签内的URL链接
1、优化效率修复运行大量任务时运行卡顿问题
2、修复大量代理时配置文件锁死程序退出问题
3、修复部分情况下mysql链接不上问题
4、修复极少云规则规则显示不了的问题
5、修复ie版本号显示不正常的问题
6、修复多页处理&问题
7、搜索增加按任务id搜索功能
8、修复下载文件filename*=的bug处理
9、其它界面和功能优化














 迅雷极速版
迅雷极速版 网易邮箱大师
网易邮箱大师 夜神模拟器
夜神模拟器 搜狗拼音输入法
搜狗拼音输入法 世界之窗浏览器
世界之窗浏览器 网易CC语音
网易CC语音 游侠对战平台
游侠对战平台 UC浏览器
UC浏览器 金山毒霸
金山毒霸 微信电脑版
微信电脑版 360压缩
360压缩 网易云音乐
网易云音乐 有道云笔记
有道云笔记 FastStone Capture
FastStone Capture 格式工厂
格式工厂 万能五笔输入法
万能五笔输入法 微软常用运行库
微软常用运行库 YY语音
YY语音 飞书文档
飞书文档 腾讯视频会议
腾讯视频会议 CPU-Z
CPU-Z 傲梅分区助手
傲梅分区助手 IDM中文版
IDM中文版 DirectX修复工具
DirectX修复工具 360驱动大师
360驱动大师 Snipaste
Snipaste 360壁纸
360壁纸 口袋动画PPT插件
口袋动画PPT插件 WPS Office
WPS Office 金山PDF阅读器
金山PDF阅读器 360手机助手
360手机助手 Root精灵
Root精灵 iTunes
iTunes 同步助手
同步助手 奇兔刷机
奇兔刷机 飞火动态壁纸
飞火动态壁纸 腾讯桌面整理
腾讯桌面整理 酷点桌面美化
酷点桌面美化 搜狗壁纸
搜狗壁纸 雨滴桌面秀
雨滴桌面秀 百度拼音输入法
百度拼音输入法 搜狗拼音输入法
搜狗拼音输入法 手心拼音输入法
手心拼音输入法 QQ拼音输入法
QQ拼音输入法 微软拼音输入法
微软拼音输入法 BandiZip
BandiZip 精灵虚拟光驱
精灵虚拟光驱 PowerISO
PowerISO 7-Zip
7-Zip 智图压缩
智图压缩 DiskGenius
DiskGenius SSD Fresh
SSD Fresh 万能低格工具
万能低格工具 安易数据恢复
安易数据恢复 CrystalDiskInfo
CrystalDiskInfo 下图高手
下图高手 可牛影像
可牛影像 Xnview
Xnview 图片去水印工具
图片去水印工具 2345看图王
2345看图王