 软件星级:3分
软件星级:3分
标签: 文字识别
领航下载站提供汉王PDF OCR 8.1.16下载。汉王PDF OCR 8.1.16拥有精准的图像型PDF的OCR识别技术,可以将文字型的PDF文件转换成可以编辑的文件。与此同时,软件还支持运用格式转换方法直接转换PDF文件成文本。欢迎下载使用。
OCR文字识别技术是什么?
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。OCR的概念是在1929年由德国科学家Tausheck最先提出来,并申请了专利。后来美国科学家Handel也提出了利用技术对文字进行识别的想法。国内最早的OCR商业应用是由中国科学家王庆人教授在南开大学开发出来的,并在美国市场投入商业使用。
汉王PDF OCR使用方法
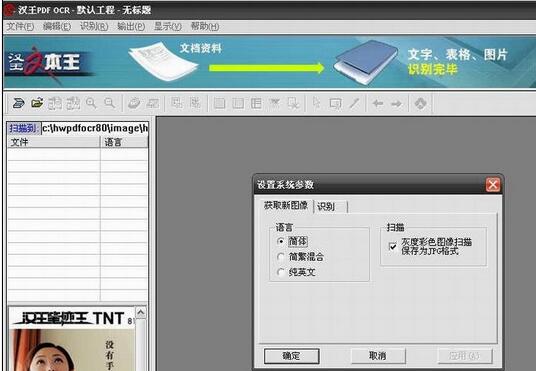
1.在开始菜单中打开OCR软件。
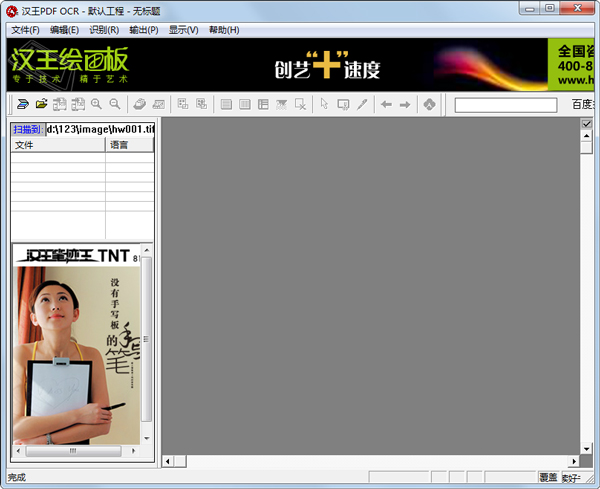
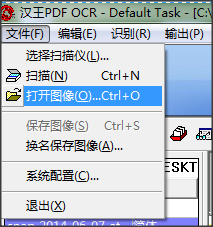
2.点击【文件】-【打开图像文件】,选择一副包含文字的图片。
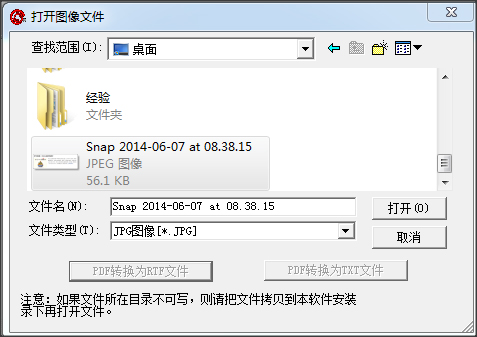
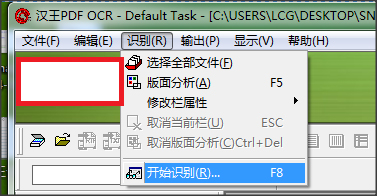
3.点击【识别】-【开始识别】。
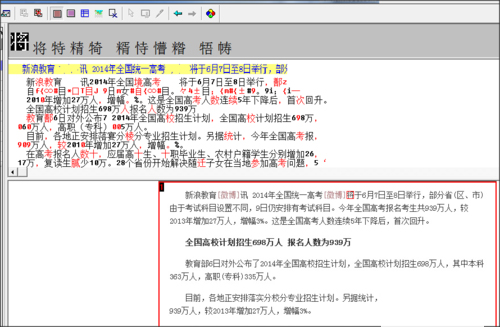
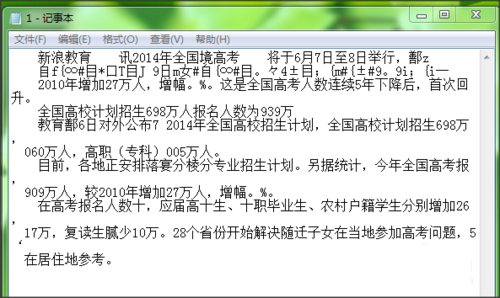
4.软件会识别出图片上的文字,可以对一些识别错误的字进行修改。
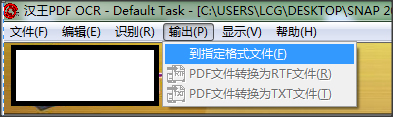
5.修改完成后点击【输出】-【到指定格式】,保存识别出来的文本。
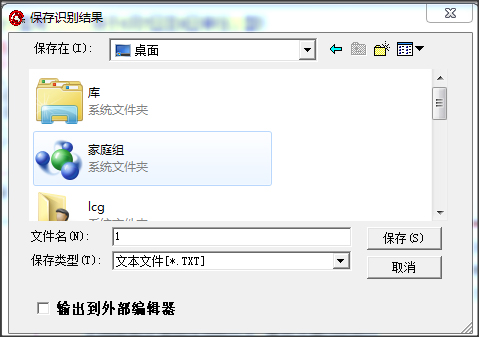
6.可以打开保存的文本,将文本复制到word等软件处进行二次编辑。
汉王PDF OCR识别过程
1.图像输入、图像前处理、预识别。
2.图像输入
对于不同的图像格式,有着不同的存储格式,不同的压缩方式,目前有OpenCV、CxImage等开源项目。
3.预处理
主要包括二值化,噪声去除,倾斜较正等。
4.二值化
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,可以简单的分为前景与背景,为了让计算机更快的、更好地识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图。
5.噪声去除
对于不同的文档,对噪声的定义可以不同,根据噪声的特征进行去燥,就叫做噪声去除。
6.倾斜校正
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
7.版面分析
将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
8.字符切割
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能。
9.字符识别
这一研究已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
10.版面还原
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变地输出到Word文档、PDF文档等,这一过程就叫做版面还原。
11.后处理、校对
根据特定的语言上下文的关系,对识别结果进行校正,就是后处理。
以上就是领航小编为您提供的汉王PDF OCR简介与使用说明,下载地址在下方,喜欢的话可以多多关注本站。
 57.02MB
57.02MB
 161MB
2.22MB
9.22MB
789KB
161MB
2.22MB
9.22MB
789KB













 迅雷极速版
迅雷极速版 网易邮箱大师
网易邮箱大师 夜神模拟器
夜神模拟器 搜狗拼音输入法
搜狗拼音输入法 世界之窗浏览器
世界之窗浏览器 网易CC语音
网易CC语音 游侠对战平台
游侠对战平台 UC浏览器
UC浏览器 金山毒霸
金山毒霸 微信电脑版
微信电脑版 360压缩
360压缩 网易云音乐
网易云音乐 有道云笔记
有道云笔记 FastStone Capture
FastStone Capture 格式工厂
格式工厂 万能五笔输入法
万能五笔输入法 微软常用运行库
微软常用运行库 YY语音
YY语音 飞书文档
飞书文档 腾讯视频会议
腾讯视频会议 CPU-Z
CPU-Z 傲梅分区助手
傲梅分区助手 IDM中文版
IDM中文版 DirectX修复工具
DirectX修复工具 360驱动大师
360驱动大师 Snipaste
Snipaste 360壁纸
360壁纸 口袋动画PPT插件
口袋动画PPT插件 WPS Office
WPS Office 金山PDF阅读器
金山PDF阅读器 360手机助手
360手机助手 Root精灵
Root精灵 iTunes
iTunes 同步助手
同步助手 奇兔刷机
奇兔刷机 飞火动态壁纸
飞火动态壁纸 腾讯桌面整理
腾讯桌面整理 酷点桌面美化
酷点桌面美化 搜狗壁纸
搜狗壁纸 雨滴桌面秀
雨滴桌面秀 百度拼音输入法
百度拼音输入法 搜狗拼音输入法
搜狗拼音输入法 手心拼音输入法
手心拼音输入法 QQ拼音输入法
QQ拼音输入法 微软拼音输入法
微软拼音输入法 BandiZip
BandiZip 精灵虚拟光驱
精灵虚拟光驱 PowerISO
PowerISO 7-Zip
7-Zip 智图压缩
智图压缩 DiskGenius
DiskGenius SSD Fresh
SSD Fresh 万能低格工具
万能低格工具 安易数据恢复
安易数据恢复 CrystalDiskInfo
CrystalDiskInfo 下图高手
下图高手 可牛影像
可牛影像 Xnview
Xnview 图片去水印工具
图片去水印工具 2345看图王
2345看图王